12.2 TensorRT 工作流及cuda-python
前言
本节将在python中采用TensorRT进行resnet50模型推理,通过一个案例了解TensorRT的工作步骤流程,为后续各模块深入研究打下基础。
本节核心内容包括TensorRT中各模块概念,python中进行推理步骤,python中的cuda库使用。
本节用到的resnet50_bs_1.engine文件,需要提前通过trtexec来生成(resnet50_bs_1.onnx通过11章内容生成,或者从网盘下载-提取码:24uq
trtexec --onnx=resnet50_bs_1.onnx --saveEngine=resnet50_bs_1.engine
workflow基础概念
在python中使用TensorRT进行推理,需要了解cuda编程的概念,在这里会出现一些新名词,这里进行了总结,帮助大家理解python中使用TRT的代码。
借鉴nvidia官方教程中的一幅图来说明TRT从构建模型到使用模型推理,需要涉及的概念。
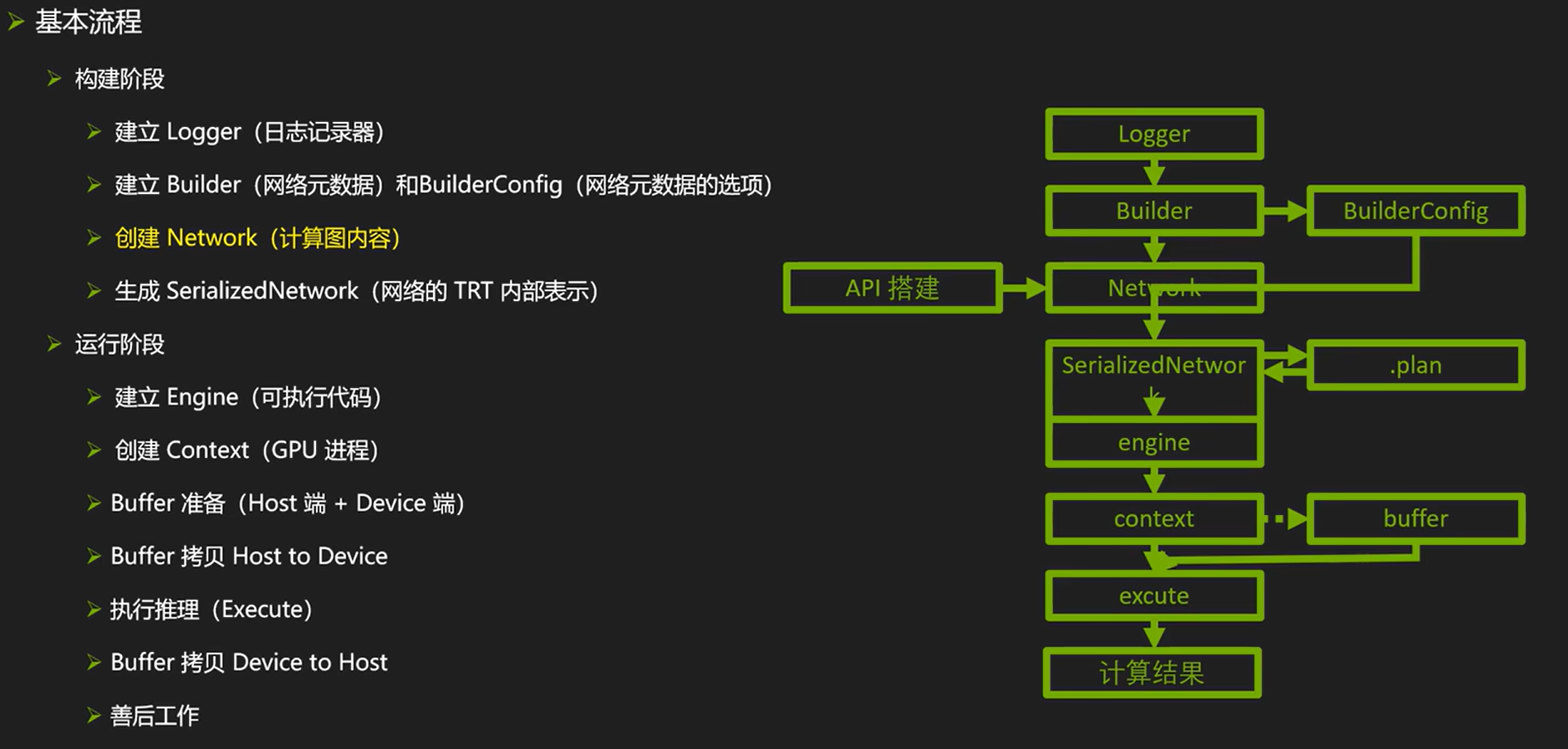
- Logger:用于在TensorRT日志中记录消息,可以来实现自定义日志记录器,以便更好地了解TensorRT运行时发生的事情。
- Builder:用于构建一个优化的TensorRT引擎,可以使用Builder来定义和优化网络
- BuilderConfig:用于配置Builder的行为,例如最大批处理大小、优化级别等
- Network:用于描述一个计算图,它由一组层组成,用来定义和构建深度学习模型,通常有三种方式获取network,包括TensorRT API、parser、训练框架中trt工具。
- SerializeNetwork:用于将网络序列化为二进制格式,可以将网络模型保存到磁盘上的.plan文件中,以便稍后加载和使用。
- .plan:.plan是TensorRT引擎的序列化文件格式,有的地方用.engine,.plan文件和.engine都是序列化的TensorRT引擎文件,但是它们有一些区别。
- .plan文件是通用序列化文件格式,它包含了优化后的网络和权重参数。而.engine文件是Nvidia TensorRT引擎的专用二进制格式,它包含了优化后的网络,权重参数和硬件相关信息。 可
- 移植性方面,由于.plan文件是通用格式,所以可以在不同的硬件平台上使用。而.engine文件是特定于硬件的,需要在具有相同GPU架构的系统上使用。
- 加载速度上:.plan文件的加载速度通常比.engine文件快,因为它不包含硬件相关信息,而.engine文件必须在运行时进行硬件特定的编译和优化。
- Engine:Engine是TensorRT中的主要对象,它包含了优化后的网络,可以用于进行推理。可以使用Engine类加载.plan文件,创建Engine对象,并使用它来进行推理。
- Context:Context是Engine的一个实例,它提供了对引擎计算的访问。可以使用Context来执行推理,并在执行过程中管理输入和输出缓冲区。
- Buffer:用于管理内存缓冲区。可以使用Buffer类来分配和释放内存,并将其用作输入和输出缓冲区。
- Execute:Execute是Context类的一个方法,用于执行推理。您可以使用Execute方法来执行推理,并通过传递输入和输出缓冲区来管理数据流。
在这里面需要重点了解的是Network的构建有三种方式,包括TensorRT API、parser、训练框架中trt工具。
- TensorRT API是手写网络结构,一层一层的搭建
- parser 是采用解析器对常见的模型进行解析、转换,常用的有ONNX Parser。本小节那里中采用parser进行onnx模型解析,实现trt模型创建。
- 直接采用pytorch/tensorflow框架中的trt工具导出模型
此处先采用parser形式获取trt模型,后续章节再讲解API形式构建trt模型。
TensorRT resnet50推理
到这里环境有了,基础概念了解了,下面通过python代码实现resnet50的推理,通过本案例代码梳理在代码层面的workflow。
pycuda库与cuda库
正式看代码前,有必要简单介绍pycuda库与cuda库的差别。在早期版本中,代码多以pycuda进行buffer的管理,在python3.7后,官方推荐采用cuda库进行buffer的管理。
- cuda库是NVIDIA提供的用于CUDA GPU编程的python接口,包含在cuda toolkit中。主要作用是: 直接调用cuda runtime API,如内存管理、执行kernel等。
- pycuda库是一个第三方库,提供了另一个python绑定到CUDA runtime API。主要作用是: 封装cuda runtime API到python调用,管理GPU Context、Stream等。
cuda库更基础,pycuda库更全面。前者集成在CUDA toolkit中,后者更灵活。
但在最新的trt版本(v8.6.1)中,官方推荐采用cuda库,两者使用上略有不同,在配套代码中会实现两种buffer管理的代码。
python workflow
正式跑代码前,了解一下代码层面的workflow:
初始化模型,获得context
- 创建logger:logger = trt.Logger(trt.Logger.WARNING)
- 创建engine:engine = runtime.deserialize_cuda_engine(ff.read())
- 创建context: context = engine.create_execution_context()
内存申请:
- 申请host(cpu)内存:进行变数据量的赋值,即完成变量内存分配。
- 申请device(gpu)内存: 采用cudart函数,获得内存地址。 d_input = cudart.cudaMalloc(h_input.nbytes)[1]
- 告知context gpu地址:context.set_tensor_address(l_tensor_name[0], d_input)
推理
- 数据拷贝 host 2 device: cudart.cudaMemcpy(d_input, h_input.ctypes.data, h_input.nbytes, cudart.cudaMemcpyKind.cudaMemcpyHostToDevice)
- 推理: context.execute_async_v3(0)
- 数据拷贝 device 2 host: cudart.cudaMemcpy(h_output.ctypes.data, d_output, h_output.nbytes, cudart.cudaMemcpyKind.cudaMemcpyDeviceToHost)
内存释放
- cudart.cudaFree(d_input)
取结果
- 在host的变量上即可拿到模型的输出结果。
这里采用配套代码实现ResNet图像分类,可以得到与上一章ONNX中一样的分类效果,并且吞吐量与trtexec中差别不大,大约在470 it/s。
100%|██████████| 3000/3000 [00:06<00:00, 467.81it/s]。
cuda库的buffer管理
采用cuda库进行buffer管理,可分3个部分,内存和显存的申请、数据拷贝、显存释放。
在教程配套代码的 model_infer()函数是对上述两份资料进行了结合,下面详细介绍cuda部分的代码含义。
def model_infer(context, engine, img_chw_array):
n_io = engine.num_io_tensors # since TensorRT 8.5, the concept of Binding is replaced by I/O Tensor, all the APIs with "binding" in their name are deprecated
l_tensor_name = [engine.get_tensor_name(ii) for ii in range(n_io)] # get a list of I/O tensor names of the engine, because all I/O tensor in Engine and Excution Context are indexed by name, not binding number like TensorRT 8.4 or before
# 内存、显存的申请
h_input = np.ascontiguousarray(img_chw_array)
h_output = np.empty(context.get_tensor_shape(l_tensor_name[1]), dtype=trt.nptype(engine.get_tensor_dtype(l_tensor_name[1])))
d_input = cudart.cudaMalloc(h_input.nbytes)[1]
d_output = cudart.cudaMalloc(h_output.nbytes)[1]
# 分配地址
context.set_tensor_address(l_tensor_name[0], d_input) # 'input'
context.set_tensor_address(l_tensor_name[1], d_output) # 'output'
# 数据拷贝
cudart.cudaMemcpy(d_input, h_input.ctypes.data, h_input.nbytes, cudart.cudaMemcpyKind.cudaMemcpyHostToDevice)
# 推理
context.execute_async_v3(0) # do inference computation
# 数据拷贝
cudart.cudaMemcpy(h_output.ctypes.data, d_output, h_output.nbytes, cudart.cudaMemcpyKind.cudaMemcpyDeviceToHost)
# 释放显存
cudart.cudaFree(d_input)
cudart.cudaFree(d_output)
return h_output
- 第3行:获取模型输入、输出变量的数量,在本例中是2。
- 第4行:获取模型输入、输出变量的名字,存储在list中。本案例中是['input', 'output'],这两个名字是在onnx导入时候设定的。
- 第7/8行:申请host端的内存,可看出只需要进行两个numpy的赋值,即可开辟内存空间存储变量。
- 第9/10行:调用cudart进行显存空间申请,变量获取的是内存地址。例如”47348061184 “
- 第13/14行:将显存地址告知context,context在推理的时候才能找到它们。
- 第17行:将内存中数据拷贝到显存中
- 第19行:context执行推理,此时运算结果已经到了显存
- 第21行:将显存中数据拷贝到内存中
- 第24/25行:释放显存中的变量。
pycuda库的buffer管理
注意:代码在v8.6.1上运行通过,在v10.0.0.6上未能正确使用context.execute_async_v3,因此请注意版本。
更多接口参考:https://docs.nvidia.com/deeplearning/tensorrt/api/python_api/infer/Core/ExecutionContext.html
在配套代码中pycuda进行buffer的申请及管理代码如下:
h_input = cuda.pagelocked_empty(trt.volume(context.get_binding_shape(0)), dtype=np.float32)
h_output = cuda.pagelocked_empty(trt.volume(context.get_binding_shape(1)), dtype=np.float32)
d_input = cuda.mem_alloc(h_input.nbytes)
d_output = cuda.mem_alloc(h_output.nbytes)
def model_infer(context, h_input, h_output, d_input, d_output, stream, img_chw_array):
# 图像数据迁到 input buffer
np.copyto(h_input, img_chw_array.ravel())
# 数据迁移, H2D
cuda.memcpy_htod_async(d_input, h_input, stream)
# 推理
context.execute_async_v2(bindings=[int(d_input), int(d_output)], stream_handle=stream.handle)
# 数据迁移,D2H
cuda.memcpy_dtoh_async(h_output, d_output, stream)
stream.synchronize()
return h_output
- 第1,2行:通过cuda.pagelocked_empty创建一个数组,该数组位于GPU中的锁页内存,锁页内存(pinned Memory/ page locked memory)的概念可以到操作系统中了解,它是为了提高数据读取、传输速率,用空间换时间,在内存中开辟一块固定的区域进行独享。申请的大小及数据类型,通过trt.volume(context.get_binding_shape(0)和np.float32进行设置。其中trt.volume(context.get_binding_shape(0)是获取输入数据的元素个数,此案例,输入是[1, 3, 224, 224],因此得到的数是1x3x224x224 = 150528
- 第3,4行:通过cuda.mem_alloc函数在GPU上分配了一段内存,返回一个指向这段内存的指针
- 第8行:将图像数据迁移到input buffer中
- 第10行,将输入数据从CPU内存异步复制到GPU内存。其中,cuda.memcpy_htod_async函数异步将数据从CPU内存复制到GPU内存,d_input是GPU上的内存指针,h_input是CPU上的numpy数组,stream是CUDA流
- 第14行,同理,从GPU中把数据复制回到CPU端的h_output,模型最终使用h_output来表示模型预测结果
小结
本节介绍了TensorRT的工作流程,其中涉及10个主要模块,各模块的概念刚开始不好理解,可以先跳过,在后续实践中去理解。
随后基于onnx parser实现TensorRT模型的创建,engine文件的生成通过trtexec工具生成,并进行图片推理,获得了与trtexec中类似的吞吐量。
最后介绍了pycuda库和cuda库进行buffer管理的详细步骤,两者在代码效率上是一样的,吞吐量几乎一致。